The WebMailer Application (v1)
PARTIE 2. DOCUMENTATION TECHNIQUE
WebMailer est une application ecrite en Java, destinee a faire du mailing cible. Exemple je viens de monter un serveur WEB pour vendre des saucisses. J'ai envie de signaler ŕ tous les webmasters qui maintiennent des pages relatives aux saucisses l'existence de mon serveur. Comment automatiser cela ? La solution consiste ŕ écrire un programme qui interroge par exemple Altavista en lui demandant quelles sont les pages qui parlent de saucisses, puis de parser les réponses pour ne conserver que les URL des pages. Ensuite, aller visiter une ŕ une les pages et récupérer les adresses emails des personnens qui maintiennent ces pages. Puis finalement leur envoyer un mail d'info concernant la création de mon site sur les saucisses. Le faire ŕ la main peut prendre plusieurs heures, avec le systčme automatique, ca devrait prendre 5 minutes.
Les performances de ce programme dependent enormement de facteurs exterieurs, la charge du reseau en particulier. Aussi il est recommande d'utiliser le programme pendant les heures "creuses" du NET. L'execution de ce programme peut etre aussi bien tres rapide (5 minutes) que d'une lenteur insoutenable !!!
Le programme WebMailer est consititue d'un seul fichier Webmailer.java . Pour avoir le code source + cette page web cliquez ici (webmailer.tar.gz). Decompressez l'archive :
Puis tapez les commandes suivantes :
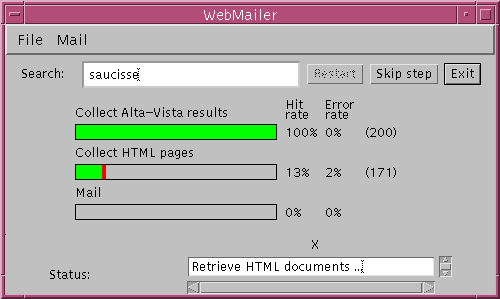
Si tout s'est bien passe, la fenetre ci-dessous apparait a l'ecran.
Note : si vous n'arrivez pas a compiler le programme une version bytecode est dans l'archive. Decompressez le fichier bytecode.tar.gz. Le fichier README contient de nombreuses infos supplementaires.
![[finder1]](finder1.gif)
L'interface graphique du programme WebMailer se decompose en 4 zones principales:
Elle permet d'acceder au menu Mail ![[finder2]](finder2.gif) qui
permet de composer les messages et de choisir le mode d'execution (Simulation
ou pas). Le mode simulation permet de ne pas expedier reellement les mails,
mais seulement d'afficher la commande unix respective a l'ecran. Ex:
mail pphung@essi.fr < message
qui
permet de composer les messages et de choisir le mode d'execution (Simulation
ou pas). Le mode simulation permet de ne pas expedier reellement les mails,
mais seulement d'afficher la commande unix respective a l'ecran. Ex:
mail pphung@essi.fr < message
![]()
La barre des commandes se decompose comme suit :
La zone d'indicateurs de progression affiche en permanence l'etat d'avancement du programme. Chaque barre de progression correspond a une phase du programme, respectivement la collecte de resultats d'AltaVista, la collecte des pages referencees par AltaVista, et l'expedition des mails. Des indices chiffres sont egalement fournis pour faciliter la lecture.
Examinons la premiere barre de progression . Elle reflete le nombre de references d'AltaVista qui on ete rapatriees.
![[progress1]](progress1.gif)
Ici 80% des references sur 200 ont ete recuperees sans erreurs. Et aucune perte n'est signalee.
La seconde barre de progression donne des informations sur les pages qui ont ete rapatriees.
![]()
Ici 13% des 171 pages ont ete recuperees sans erreurs. Par contre 2% des documents ont etes perdus suite a des coupures de connexion.
![[status]](status.gif)
La barre de status indique en permanence l'etat de l'application. Si un caractere X clignote, la recherche de documents est en cours. Des messages informent l'utilisateur :
Cette fenetre permet de composer le message qui sera envoye a la mailing -list que l'on obtient a la fin de l'execution du programme. Pour invoquer cette fenetre, il faut passer par l'item Compose du menu Mail. Une fois le message compose, tapez sur le bouton OK ou bien Cancel si vous avez change d'avis.
Voici les fonctionnalites offertes par la version actuelle (v1) de WebMailer :
Toutes les phases du programme ont fait l'objet de tests. Cependant des tests a grande echelle avec envois de mails reels n'ont jamais ete realises pour des raisons evidentes. Submerger les mailboxes de plusieurs centaines de personnes a chaque essai du programme n'est pas souhaitable. Pour la realisation de tels tests, nous avons utilise un fichier d'emails de remplacement "fake_r4" contenant nos emails perso pphung@essi.fr & haquet@essi.fr . Ainsi des tests ont pu etre realises sans perturber de nombreuses personnes inutilement.
Dans la version actuelle, par defaut le mailing est simule. Meme si l'option de simulation est enlevee, il ne se passe rien, car la ligne permettant d'utliser le fichier reel d'emails "r4" a ete mis en commentaire !!! Pour l'utiliser, retirer le commentaire et recompiler l'application.
Mais l'utilisation de cette fonctionnalite se fera sous votre responsabilite !
Avant d'aborder les aspects purement techniques, nous aimerions exposer les raisons qui nous ont pousse a choisir ce sujet parmi tant d'autres. L'eventail des sujets proposes cette annee dans le cours Internet etait important. De plus il etait possible de proposer des sujets personnels. Aussi, nous avons prefere, comme l'occasion nous etait offerte de choisir un sujet moins "classique" qu'une application purement Java. Notre choix s'est porte sur le mailing cible.
Ce sujet nous permettait non seulement d'aborder la programmation en Java mais aussi des aspects reseaux inherents au sujet, a savoir l'utilisation de sockets pour l'etablissement de connexions avec des serveurs distants, l'utilisation du protocole HTTP. Une surprise etait au rendez-vous. L'univers des moteurs de recherches s'est avere etre un monde saisissant dont les seules limites sont (il me semble) celles de l'imagination (des moyens financiers ?).
Nous presentons dans cette partie les renseignement que nous avons glanes sur le moteur de recherche AltaVista. La plupart des informations presentees sont issues d'AltaVista. Pour plus d'informations cliquez ici.
Lorsqu'une requete est adressee AltaVista, le moteur de recherche renvoie au maximum 10 references par pages. Dans tous les exemples qui vont suivre le critere de recherche est le mot "saucisse". Il permet de faire des tests convenables (200 documents), sans avoir un nombre de pages reponse enorme (ex: ibm -> 2 millions de documents).
La ligne suivante (presente sur la premiere page reponse) permet de connaitre de nombre potentiel de reponse.
Documents 1-10 of about 200 matching the ...
Dans cet exemple il faudra rapatrier en tout 20 pages reponses (200/10) pour avoir toutes les reponses d'AltaVista. Voici les requetes correspondantes :
Notre programme procede de meme pour simuler le comportement du navigateur. La generation des requetes est realisee dans l'instance de la classe RobotAltaVista.
Pour l'instant notre programme ne supporte que les requetes simples d'AltaVista. Mais il est tres facile de les integrer. Si l'on desire malgre tout faire une recherche avancee, c'est possible. Il suffit de faire le travail de parsing realise normalement par la page HTML d'AltaVista a la main.
Exemple : requete avancee pour retrouver toutes les pages qui comportent une image nommee "comet.jpg".
Tous nos criteres de recherche sont convertis en minuscules car AltaVista est case-sensitive. En effet les majuscules forcent la casse au niveau au d'AltaVista ce qui limite enormement les nombre de reponses potentielles.
Exemple : le mot turkey dans une requete va matcher avec toutes les occurences de turkey, Turkey, tUrkey, TURKEY dans les documents.
Le programme est construit autour de 2 classes principales : RobotAltaVista et RobotTelnet. La premiere constitue le coeur du programme. C'est elle qui initie toutes les recherches de document sur le Web. La seconde permet de rapatrier les documents. Ces deux classes sont derivees de la classe Thread.
Les classes qui gravitent autour des 2 classes principales n'ont essentiellement qu'un role d'embellissement, destine a ameliore le confort d'utilisation de l'application.
Le programme dans son etat actuel peut etre decoupe en phases sucessives:
Pour des raisons de performances (cf Timeout d'AltaVista) le programme utilise plusieurs fichiers de travail intermediaires :
Dans les premieres versions du programme, nous avons ete confrontes a un probleme majeur. Les sockets que nous utilisions pour rapatrier les documents etaient tres souvent prematurement fermes avant l'acquisition totale des documents.
En effet dans notre premiere approche, l'operation de filtrage des lignes contenant les URLs etait realise pendant la connexion (pour sauver de l'espace disque). Or cette operation -gourmande en temps- entrenait le declenchement d'un timeout sur Alta-Vista qui coupait tout simplement la liaison. Ce probleme est maintenant resolu.
Nous avons adopte la demarche inverse : favoriser la vitesse de rapatriement des documents au detriment de l'espace disque utilise. Plus aucun traitement n'est fait pendant que le socket est actif. Les documents sont sauves dans leur integralite sur le disque, puis filtres par la suite.
Dans les premiers temps une approche sequentielle a ete retenue. Recuperer les documents les uns apres les autres. Cette demarche aboutissait souvent au blocage total du deroulement de l'application, lorsque la demande d'un document n'aboutissait pas ou mettait enormement de temps. C'est pour cela que nous n'avons pas retenu cette strategie.
Pour palier au probleme precedent, nous avons utilise des threads pour rapatrier tous les documents en parrallele. Cette technique permet de pousuivre le deroulement global de l'application. Meme si certains documents mettent du temps a arriver, il est possible d'initialiser d'autres demandes.
Dans notre programme, cette approche multi-threads dans la recherche de document est utilisee a deux moments :
Dans un soucis de convivialite nous avons rajoute une interface graphique a notre programme. Or l'execution en parallele de nombreux threads (de recherche de documents par exemple) gourmande en temps peut perturber l'acces a l'interface voire empecher son raffraichissement. Pour palier a ce probleme une priorite basse a ete affectee aux threads de recherche de document (qui sont en nombreux).
Le filtrage des adresses email dans les documents est un point assez delicat. Quels sont les criteres qui permettent de distinguer une simple chaine de caracteres d'une adresse email valide?
La solution que nous avons retenu en premier repose sur la presence de tag "mailto:". En effet lorsque l'on recontre ce type de tag dans un document, la probabilite pour que l'adresse qui suit soit bonne est nettement superieure. Mais ce tag ne garantit pas que l'adresse est valide. Les causes qui rendent les adresses potentielles invalides sont nombreuses : le document n'est peut-etre pas a jour, dans ce cas l'adresse peut ne plus exister, les fautes de frappes des proprietaires des pages ne sont pas exclues... Cependant cette approche restreint enormement le nombre d'emails potentiels. Car les adresses ne sont pas toujours contenues dans des tags mailto: au sein des documents. C'est pour cela que nous avons adopte une autre solution.
Une adresse email c'est une chaine de caractere suivie d'un @ puis d'une autre chaine de caractere contenant un ou plusieurs points (voire pas du tout). Cette methode permet de recuperer plus d'adresses email. Bien sur la viabilite de telles adresses est moindre que celle rencontree dans la premiere solution. Neanmoins nous avons fait le choix de ratisser large, meme au risque d'atteindre des personnes non concernees, plutot que de risquer de ne pas informer des personnes "potentiellement concernees" faute de tag mailto: dans leurs pages.
Note : notre programme detecte et supprime les doublons dans les emails.
De nombreuses ameliorations sont possibles, car a ce stade notre programme n'est qu'un prototype.
Voici les voies qui nous paraissent les plus interresantes :
Bien que dans notre application certaines recherches se font en parallele, on peut distinguer 3 phases sucessives dans le deroulement du programme :
Une phase ne debute que lorque la precedente est terminee. Cela peut entrainer une perte de temps. En effet Alta-Vista peut mettre enormement de temps entre l'envoie de sa premiere et de sa derniere derniere page reponse.
L'idee consiste a initialiser des recherches de documents des reception de reponses d'Alta-Vista meme partielles. Ainsi du point de vue du programme, les deux phases de recuperation serait fusionnee.
Afin d'accroitre l'efficacite de la recherche de reference de documents. Il serait judicieux de faire appel non pas a un seul moteur de recherche comme Alta-Vista mais a plusieurs (Excite, InfoSeek, Lycos, OpenText, WebCrawler).
Le format des requetes d'un moteur de recherche a un autre est similaire et facilement adaptable. Voici un exemple pour les moteurs de recherche AltaVista et OpenText:
AltaVista:pg=q&what=web&fmt=.&q=_________
OpenText:SearchFor=________&mode=and
Cette approche est tres interessante et fait l'object de nombreuses recherche actuelles.
Keyword: Meta-SearchEngines.
Comme notre application est gourmande en acces disque, un maniere simple de l'optimiser serait de passer par l'utilisation de bufferpour les oprations de filtrage/sauvegarde des documents.
Il serait aussi tres interressant de creer une applet capable de transmettre les criteres de recherche a l'application WebMailer. La possibilite d'utilisation de l'application serait alors offerte a toute personne ayant acces a un navigateur.
La realisation de ce projet a ete en tout points enrichissante. Il nous a permis de decouvrir les possibilites mais aussi certaines limites du langage Java ainsi que l'univers des moteurs de recherche qui est un monde saisissant.
Le seul regret que nous avons, c'est de ne pas avoir eu assez de temps pour explorer toutes les voies que nous proposons (cf. Ameliorations possibles). Notre sentiment est qu'un sujet plus etoffe batit autour du sujet original ferait un tres bon projet d'annee.
Si vous avez des commentaires ou des questions : Philippe PHUNG <pphung@essi.fr>