
Main Page - Help
- Download - Screen
Shots
Once you have download the Slurp package, you just have to decompress
it.
It will made a directory called Slurp.
Type "cd Slurp" to enter the directory (hope you're not stupid
=) )
You must have your java full configured with PATH and CLASSPATH
settings ok !
Then juste type "java Slurp" to launch Slurp application.
Two windows will pop-up : a log window and an interface window.
The log window
this windows is here just to control
that Slurp is running fine :)

The Interface
This is the heart of Slurp. It will help
you to configure your downloads.
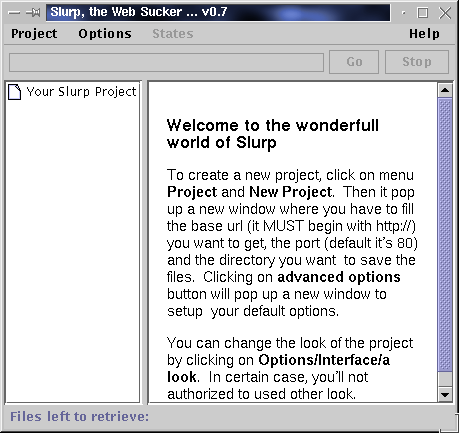
In the right window, there's help for everything. Just read this windows !!!!
How launch download in command line ??
just type "java Slurp [options] http://your.url.you/want/to/get/".
Options can be :
- -t number => number of threads that will be launched !
- -samehost => slurp will get only files that are in the same host that the first url.
- -noparent => slurp will get files in the sames server and under the first page.
- -followftp => not implemented yet.
- -overwrite => will overwrite the local files.
- -nohost => won't create directory for the server name.
- -nodir => save all files in the curent dir.
- -depth number => the depth of links to be slurp.
- -q number => quota in MegaOctet
- -d string => directory to save all the files
- -l login -p password => to access protected pages.
- -r number => number of retry for the pages in case of failure.
- -ext string => files to be excludes. (example : "gif,mpg,exe").
- -aut string => files to be get (string same syntaxe that -ext).
- -mirroring => mirroring sites.
- -agent string => send browser ident to remote server.
- -proxy host:port => enable proxy.