| Bruno Gery Emmanuel-Pierre Hébé |
Cliquez ici pour télécharger l'archive du projet

|
Le but de notre projet était de réaliser un logiciel rapatrieur de sites Web en Java. Ce logiciel devait entre autres permettre le rapatriement de documents en parallèle, et la possibilité de stopper un téléchargement, et de le poursuivre ultérieurement à partir d'un fichier de sauvegarde.
Mode de fonctionnement du grabber : Un téléchargement s'articule autour d'une liste d'URLs ( EntiteURL ).
Chaque élément de cette liste comporte des informations (telles que : URL en cours de parsing, URL
parsée, URL téléchargée, nom du fichier où il est sauvé ...). Au départ la liste contient un seul
élément : l'URL passée en paramètre.
Pour une liste donnée, il y a trois threads qui tournent en permanence : une thread piocheur et
deux thread parseur. La thread parseur parse les fichier HTML et ajoute dans la liste
les documents référencés par la page HTML parsée. La thread piocheur pioche dans la liste
d'EntiteURL à télécharger et instancie une thread téléchargement qui va rappatrier le fichier. Quand
une thread téléchargement meurt, elle en informe la thread piocheur, qui pourra si besoin est,
en créer une autre.
Une thread téléchargement va chercher un document à son URL, le sauvegarde sur le disque local, et
défini les attributs (Mime/Type, compteur d'erreurs de téléchargement...) de l'entiteURL qui vient
d'être téléchargé. Le compteur d'erreurs sert à effectué plusieurs tentatives quand une adresse
ne répond pas.
A chaque rappatriement correspond à une thread et une liste d'entité URL. Ainsi, on peut lancer
plusieurs rappatriement simultanément sur des sites différents. Pour chaque rappatriement ayant,
en interne, plusieurs téléchargement de fichiers en parallèle. Il est bien évident qu'il ne faut
pas abuser du nombre de rappatriement simultanés.
De plus, le nombre de téléchargement parallèle pour un rappatriement ne doit pas être trop
important car les O.S. ne supportent qu'un petit nombre de fichiers ouverts simultanément (de
l'ordre de 40 à 50 sur SunOS lors de nos tests). Un trop grand nombre de fichiers ouverts provoque
des erreurs de téléchargement au même titre qu'une adresse qui ne répond pas.
Nous avons essayer de réaliser une interface esthétiquement agréable et simple d'utilisation. Nous
l'avons donc réaliser gr&acric;ce à la librairie Swing de Sun.
Il nous a donc fallu apprendre la bibliothèque Swing pour réaliser notre interface en fonction des
possibilités que nous offrait Swing.
Nous sommes satisfait de l'interface du logiciel, mais, l'utilisation de Swing (bibliothèque assez
lourde et gourmande en mémoire) provoque des temps d'attente important lors des raffraîchissements
que nous n'avions pas lors du developpement du moteur de l'application à l'aide d'une interface
rudimentaire Awt.
En particulier, l'affichage de l'arborescence du site rappatrié consomme une quantité de ressources
trop importante,ce qui provoque un délai d'attente lors de la construction de l'arbre en fin de
rappatriement qui est assez pénible.
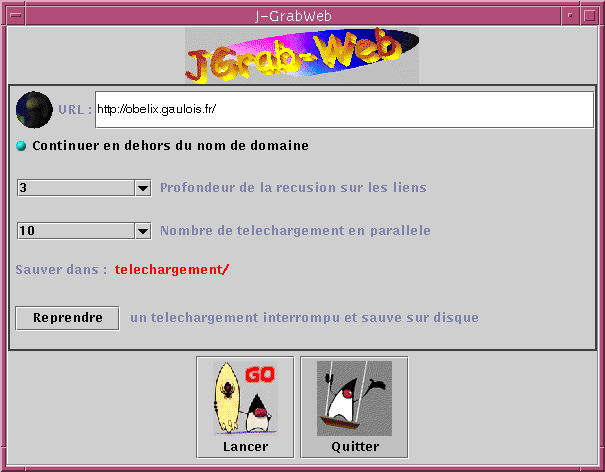
Voici la fenêtre principale de JGrab-Web.
L'interface comporte un champ de saisie pour l'URL, une check-box permettant de
spécifier si le rapatriement peut déborder du site téléchargé, un combo-box (par ailleurs
éditable ) permettant de spécifier la profondeur à laquelle il faut descendre
récursivement sur les hyper-liens à partir de la page initiale, une autre combo-box
permettant de spécifier le nombre de téléchargement maximum tournant en parallèle pour le
rappatriement, une zone indiquant le dossier où sera sauvegardé le site rappatrié. Un
bouton permettant de reprendre un téléchargement sauvé sur disque au point où en était
le téléchargelement quand il a été arrété.
Plus bas, se trouvent deux boutons (
![]() et
et
![]() )
permettant respectivement de lancer le rappatriement et de
quitter l'application.
)
permettant respectivement de lancer le rappatriement et de
quitter l'application.
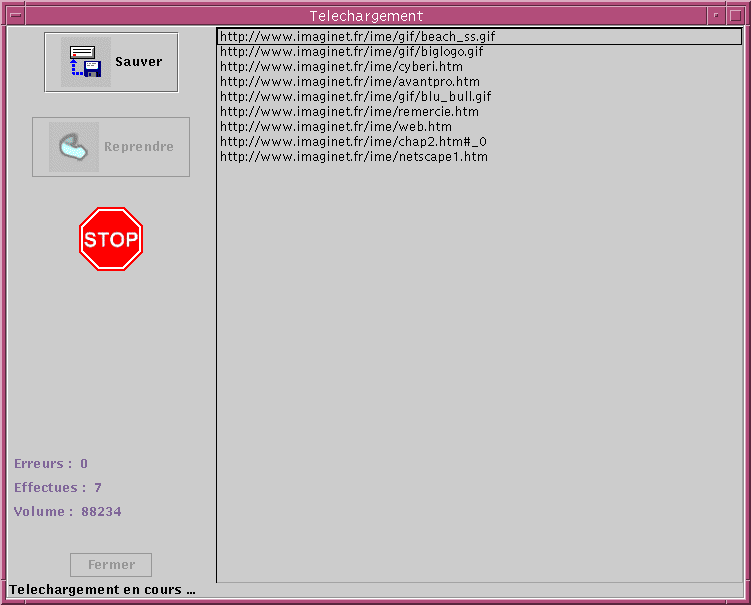
Dans la partie de droite s'affichent les téléchargements en cours. On y voit
l'URL du fichier que chaque thread est en train de rappatrier.
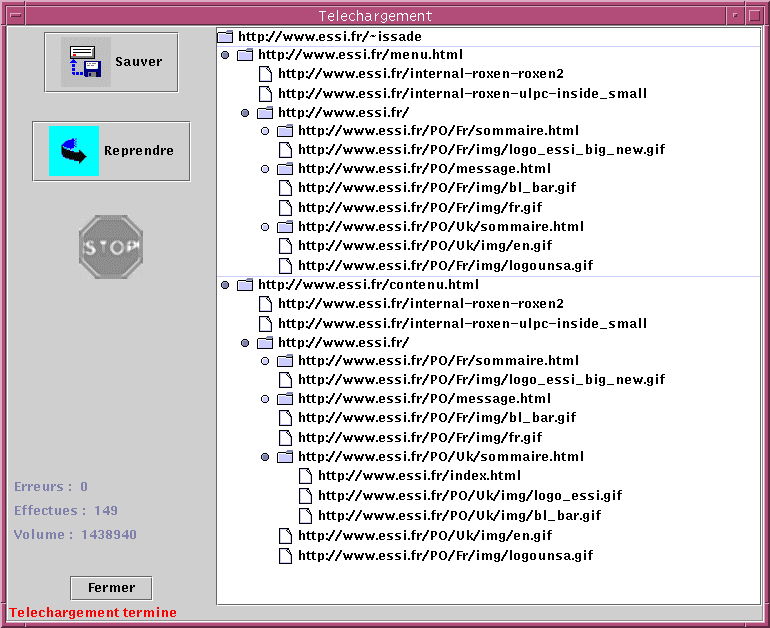
Une fois le téléchargement terminé, cette partie disparaît et fait place à l'arborescence
des liens hyper-textes téléchargés.
ATTENTION : il ne s'agit pas d'une arborescence de fichier telle qu'on la trouve dans un gestionnaire de fichiers (type explorateur windows, Tk Desk...), mais de l'arborescence hypertexte developpée à partir de l'URL demandée. Chaque dossier correpond donc à une page HTML, et les éléments contenus dans le dossier aux URL contenus dans cette page.
Il serait pratique de pouvoir afficher un fichier HTML ou une image d'un simple clic sur un élément de l'arborescence en utilisant le Bean HotJava de Sun. Cela permettrait en visualisant le contenu de la page de savoir s'il serait interessant de poursuivre le rappatriement plus profondement à partir de ce noeud.
Chaque de noeud de l'arbre aurait une petite icone qui permettrait d'un seul coup d'oeil de voir le Mime/Type de cet objet.
Permettre de ne pas afficher l'arborescence (dans le cas de gros rappatriements par exemple ), vu le délai de génération et d'affichage de l'arbre étant pénalisant.
Afin de réaliser notre projet, nous avons utilisé la libraire adc qui nous a permis de séparer les tags HTML, et recupérer ainsi tous les liens, images... Nous avons sommes aussi de la librairie Swing livrée en standard dans le Jdk afin de développer l'interface graphique.
Pour utilisez JGrab-Web, il suffit de-compactez l'archive dans un répertoire (JGrab-Web par exemple...). Ensuite, assurez-vous que la librairie Swing 1.0 est bien installée, et que votre environnement est configuré pour l'utiliser. Ensuite tapez :
java JGrab-Web
Swing 1.0 n'étant pas installé à l'ESSI, nous avons dû l'installer sur notre compte
(~gery/java/swing/). Le fichier environnement à utiliser est swingconf (disponible dans
l'archive où chez ~gery/swingconf).