Introduction
Remerciements
Je tiens à remercier François Dagorn pour avoir publié
sur le web son cours sur les proxy-cache, dont je me suis très largement
inspiré.
Principe de fonctionnement
Pourquoi utiliser un proxy ? (1)
Pour des raisons de sécurité
-
Un Proxy fait office de firewall (pare-feu)
J'ai un réseau local de machines dans mon entreprise, non connectées
à l'Internet. Une seule est connectée sur laquelle tourne
un Proxy. Elle donne la connectivité Internet aux machines locales,
mais ces dernières demeurent invisibles à l'extérieur.
-
Certains proxies comme Squid
peuvent faire office d'accélérateur http
Ils peuvent être vus comme un unique serveur http, mais en réalité
il masque plusieurs vrais serveurs http situés peut-être
derrière le firewall. Un accélérateur http centralise
les données des différents serveurs dans un cache.
Pourquoi utiliser un proxy ? (2)
Pour contôler l'utilisation d'Internet
-
On peut filtrer les protocoles.
Autoriser la secrétaire à juste faire du mail mais le
développeur à faire du web et du ftp. On peut interdire les
rlogins, telnet, etc...
Soulager le réseau
-
Le Proxy peut "cacher" les documents déjà demandés.
Cache = copie locale d'un document distant. Le cache garde localement
une copie de tous les documents qu'il transmet. Si on demande au cache
un document qu'il possède déjà, il peut le délivrer
sans délivrer de requête au serveur.
Pourquoi utiliser un proxy ? (3)
Donner accès à des protocoles que les clients WWW ne connaissent
pas
-
Exemple : le protocole WAIS (Wide Area Information Search) est obligatoire
pour accèder à la bibliothèque de l'INRIA. Il faut
positionner www.inria.fr port 80 comme Proxy WAIS dans son navigateur.
Contenu d'un cache WWW
Les documents stockés dans un cache y demeurent en fonction :
-
D'une date d'expiration (en-tête HTTP expire)
-
D'une durée de vie estimée à partir des dates de dernière
modification (en-tête HTTP Last-Modified)
-
D'une durée de vie fixée arbitrairement (pour chaque type
de document), de la fréquence d'utilisation du document, etc...
-
On peut indiquer au cache que certains documents ne doivent jamais être
cachés: les procédures CGI, les documents soumis à
identification d'utilisateur, certains server side includes, etc...
Que cacher, que ne pas cacher ?
-
On ne doit pas cacher les numéros de carte de crédits saisis
par les gens lors d'achats en ligne !
-
Les résultats de scripts.
-
Les bandeaux publicitaires tournants (non, sérieusement)
-
Les sites dont le contenu change souvent (les dépêches AFP,
www.cnn.com, etc...)
-
On doit cacher les sites que les gens fréquentent le plus et qui
sont statiques !
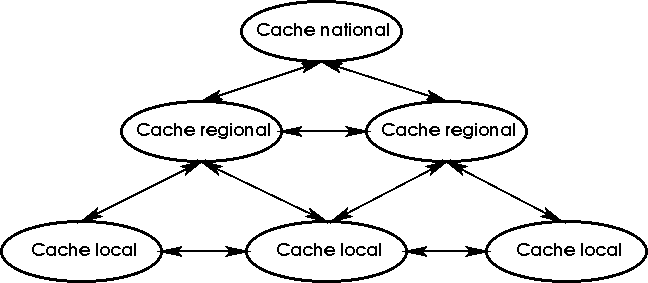
Réseau de caches WWW (1)
Un réseau de cache WWW peut être mis en oeuvre de la façon
suivante :
Réseau de caches WWW (2)
On distingue deux types de liaisons inter-caches :
-
Hiérarchiques, des mises à jour de cache s'effectuent en
cascade.
-
Transversales, simples sondages des caches voisins.
Les liaisons de voisinage donnent des résultats (taux de succès
dans les accès) très aléatoires
-
A conseiller en cas de d'homogénéité de communauté,
réseau de caches thématiques, etc...
-
Par exemple réseau des universités, etc...
Réseau de caches WWW (3)
La construction d'un réseau de caches WWW hiérarchique s'opère
en respectant les contraintes suivantes :
-
A chaque niveau de la hiérarchie, les caches doivent être
installés sur les tronçons les plus rapides du réseau
utilisé.
-
Le dimensionnement de la taille d'un cache de niveau n doit
tenir compte de la taille des caches de niveau n-1 ainsi
que du nombre d'accès journaliers de chacun d'entre eux.
Le mirroring (1)
Une autre méthode complémentaire pour soulager le réseau
consiste à établir des miroirs régionaux ou nationaux
des serveurs WWW ou FTP les plus fréquentés.
-
Quelques miroirs connus en France :
Qu'est-ce qu'un logiciel de mirroring ? (1)
Un outil capable de rappatrier une page web ou un répertoire
ftp, puis de déduire en fonction de certaines règles les
documents qu'il faut qu'il rappatrie ensuite.
-
C'est un logiciel récursif.
Il faut utiliser ce type de logiciels avec attention sinon ils
peuvent vous rappatrier l'Internet entier ! Tiens, une pub microsoft dans
ma page, hop, je télécharge tout www.micorosoft.com !
-
Certains robots sont très intelligents
...et ne téléchargerons pas les documents non modifiés
depuis le miroir précédent, modifieront automatiquement les
liens dans les pages pour autoriser une consultation locale, etc...
Qu'est-ce qu'un logiciel de mirroring ? (2)
-
Pour éviter de se faire copier son web tous les soirs :
Une norme permet à l'aide d'un fichier robot.txt, que
l'on place sous la racine de son serveur web, de filtrer les robots.
-
Quelques logiciels de miroir sous Unix :
-
wget (dans ~buffa/bin),
-
webcopy, mirror, w3mir, etc...
Mirroring + Cache : mais bien sûr !
L'outil de mirroring wget sait utiliser un cache web, il suffit de positionner
les variables.
% export http_proxy=http://mycache.essi.fr:3128/
% export gopher_proxy=http://mycache.essi.fr:3128/
% export ftp_proxy=http://mycache.essi.fr:3128/
Donc si ce soir je lance un mirroir d'un site web avec wget, je vais récupérer
toutes les pages web avec les images, etc... mais comme je passe par le
cache, il y aura aussi une copie dans le cache, donc toutes les personnes
qui utilisent ce cache pourront profiter du miroir ? Hmmmm....
Mirroring + Cache : doit-on l'utiliser ?
-
Ca marche effectivement, surtout que wget possède une option spécialement
faite pour le mirror+cache : l'option --delete-after qui signifie
: télécharge tout mais efface dès que c'est arrivé
! Puisque c'est dans le cache, inutile d'avoir deux fois les données
!
wget --mirror -np --delete-after http://www.essi.fr/~buffa
A utiliser avec précaution car il faut être sûr que
toutes les pages seront bien demandées par les utilisateurs du cache,
sinon on mirrore pour rien !
Utile pour "pré-loader" des fichiers qui ont beaucoup de succés.
Les caches des clients (navigateurs) ou "caches personnels"
Les clients WWW proposent bien souvent de gérer un cache privé:
-
De type persistant sur disque, pratique mais dangereux !
-
100 utilisateurs disposant d'un cache privé de 10 mégas =
10.000 mégas !... à déconseiller !
-
A l'ESSI : le serveur Roxen a un module de cache et 3,6 Go sont alloués
pour éviter que chaque étudiant ait son propre cache disque
(à l'ESSI : un accés/minute)
-
En mémoire :
-
Nécessaire à la navigation avant/arrière entre les
pages. On a pas envie de recharger les pages vues 2 minutes avant la page
courante !
Quel logiciel utiliser ? (1)
Nombreux logiciels !
Dans le domaine public on trouve principalement :
-
Harvest Cached : développements stoppés, efficace
dans les accès au cache, adapté aux réseaux de caches,
sert également d'indexeur de documents. Utilisé au CICA pour
indexer et cacher les documents relatifs aux offres d'emploi.
-
Des modules proxy pour certains serveurs (Apache, Roxen...)
-
Squid : développé
à partir de la dernière version de Harvest Cached, conseillé
dans le cadre du projet Renater-cache. C'est celui que nous allons
utiliser pour nos TDs ! Nombreuses possibilités.
-
Certains logiciels sont spécialisés dans une seule fonction,
comme Socks, le gestionnaire de firewall sous Unix. Il ne fait pas
de cache mais propose des filtres puissants pour les différents
protocoles (telnet, rlogin, ftp, etc...). Dans ce cas on peut par exemple
utiliser socks pour la sécurité et le module de cache d'Apache.
Quel logiciel utiliser ? (2)
On trouve des produits commerciaux
-
Allez donc voir chez Netscape ou chez Microsoft ! Ces proxies sont le plus
souvent utilisés pour des raisons de sécurité.
-
Note importante : aujourd'hui aucun de ces deux produits commerciaux n'arrive
à la cheville de Squid d'après les newsgroups, en particulier
la gestion des serveurs hiérarchisés est réduite à
sa plus simple expression sur les produits Microsoft et guère mieux
avec le Proxy de Netscape (un seul parent par cache, pas de caches latéraux).
Le projet Renater-cache
Construction d'un réseau hiérarchique de caches WWW au sein
de la communauté RENATER :
-
Voir http://vespa.cru.fr/renater-cache/renater-cache.html
-
Installation de caches régionaux, fils d'un cache national disposant
de 20 gigas octets (DEC Alpha Server1000A, 256 Mo ...).
-
Des caches locaux doivent être implantés dans tous les établissements
désireux de participer à l'opération. La taille du
cache local peut être comprise entre 300 mégas et 1 giga octet.
-
Les caches locaux sont fils des caches régionaux dont la taille
peut varier de 2 à 5 gigas octets.
Squid (1)
-
Gestion des hiérarchies de caches et des caches latéraux
(via des requêtes UDP).
-
Complexe mais ultra-puissant : on peut par exemple avoir un cache distribué
et non redondant (partager de l'espace disque sur plusieurs machines sans
jamais cacher la même chose ni faire de copies inter-caches, impossible
à faire avec les outils Microsoft ou Netscape)
-
Interfaçage possible avec des caches Harvest, Microsoft, Netscape,
Novell, etc...)
Squid (2)
-
Supporte les raffraichissements conditionnels ( If-Modified-Since),
la hiérarchie des caches est alors ignorée.
-
Peut fonctionner comme un accélérateur http.
-
Performances supérieures à un serveur http standard.
Squid + Apache est en général plus performant qu'Apache seul.
-
Peut servir à optimiser les performances réseau :
le vrai serveur http est sur un sous-réseau lent mais l'accélérateur
tourne sur une machine connecté à l'internet par une ligne
rapide. Comme les données sont cachées, les accés
prennent moins de temps.
-
Sécurité : on cache un serveur http sensible derrière
Squid. On peut filtrer les personnes qui peuvent y accéder de manière
plus sûre qu'avec un simple serveur web.
Squid (3)
-
Conditions d'arrêt et de redémarrage du cache bien gérées
(on ne perd pas forcément le contenu du cache lors d'un redémarrage).
Remarque : il est conseillé de redémarrer les caches au moins
une fois par semaine pour éviter que la mémoire ne soit trop
fragmentée)
-
Contrôle des accès très (trop ?) puissant, Squid
utilise une couche nommée AccessControlList (ACL) pour contrôler
l'accès au cache, aux URL (ni cache, ni proxy pour tel protocole,
etc...)
-
Peut fonctionner comme un serveur ftp (sur le cache)
-
Interface de configuration sous forme de page HTML (optionnelle).
-
Attention, un cache harvest n'est pas directement compatible avec
un cache Squid (il faut passer un petit script sur le log).
Squid (4)
Attention au choix du système d'exploitation :
Attention à la taille mémoire :
-
Un cache de 50 000 objets nécessite sous SunOS un processus occupant
17 mégas de RAM
-
Un cache de 110 000 objets nécessite sous Linux un processus
occupant 28 mégas de RAM
-
... et avec la version 1.1.beta4 de squid, pour un espace disque de 4Go
affecté au cache conduisant à environ 220000 objets, le process
fait pratiquement 80Mo. La machine doit donc avoir au moins 128Mo de RAM
pour fonctionner correctement !
Squid (5)
Attention à ce qui tourne sur la machine
-
Il est conseillé, si on installe un cache à grande échelle,
d'avoir une machine dédiée à cette seule fonction.
-
Eviter de lancer des daemons inutiles, éviter d'indexer tous les
fichiers dans une petite base de données (updatedb sous Linux),
sinon on va indexer tout le cache !
